LLM Resources
在中,是否可以使用UUID作为主键?
全局唯一标识符(UUID ),是一种允许开发者生成全局唯一ID的方法,其设计确保了无需了解其他系统即可保证ID的独特性。
在分布式架构中,多个系统和数据库负责记录的创建,UUID格外有用。或许,你可能认为将UUID用作数据库主键是一个不错的主意,但如果使用不当,它可能会严重影响数据库性能。
在本文中,我们将详细剖析在MySQL数据库中使用UUID作为主键的弊端,在这个过程中也详细的了解一下UUID多个版本构成。
UUID 的多个版本
截至目前,UUID有五个正式版本与三个提议版本。让我们来看每个版本的工作原理以更好地理解它们的不同。
UUIDv1
UUID 版本 1 是基于时间的 UUID,其结构如下:
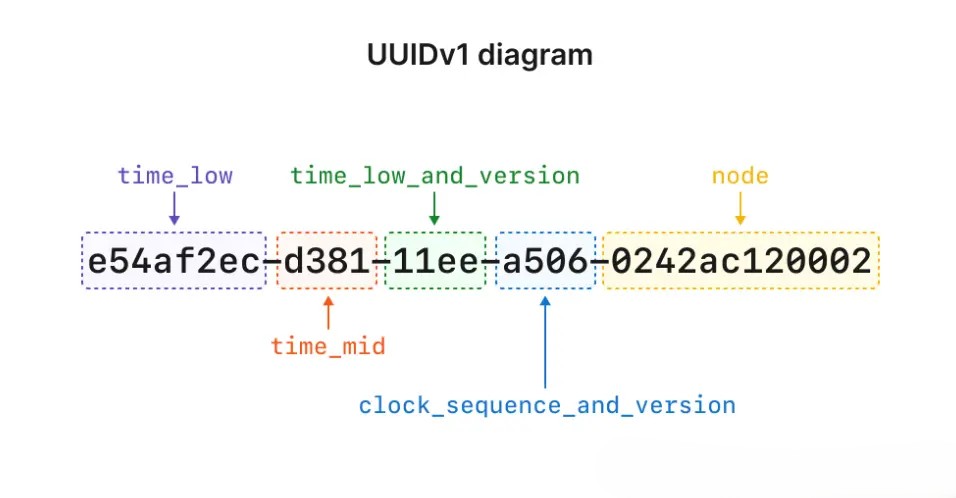
尽管现代计算大多使用 UNIX 时间戳 (从 1970 年 1 月 1 日开始) 作为基础,UUID 实际上使用了另一个时间起点 —— 1568 年 10 月 10 日,这一天是格里高利历 开始被广泛使用的时间。
UUID 中嵌入的时间戳从这一日期起每 100 纳秒递增,用于设置 time_low、time_mid 和 time_hi 部分。
UUID 的第三部分包含了版本号以及 time_hi,且该部分的第一个字符始终标志着该 UUID 的版本。这种结构适用于所有版本的 UUID(后续示例中也会指出)。保留部分称为 UUID 的变体,它决定了 UUID 内部的位使用方式。最后一部分是 node,表示生成 UUID 的系统的唯一地址。
UUIDv2
与版本 1 相比,UUID 版本 2 对结构做出了一些改变,将 low_time 部分替换为 POSIX 用户 ID。
理论上讲这种 UUID 可以追溯到生成它的用户账户。但由于 low_time 是 UUID 变动性的重要来源,替换这个部分会增加发生冲突的可能性。因此,这个版本很少被使用。
UUIDv3 和 UUIDv5
UUID 的版本 3 和版本 5 非常相似。这些版本旨在以确定性方式生成 UUID,也就是说,给定相同的信息能够生成相同的 UUID。
这些实现使用两种信息:一个命名空间(本身就是一个 UUID)和一个名称。这些值通过哈希算法生成 128 位的值并表示为 UUID。
两者的主要区别在于:版本 3 使用 MD5 哈希算法,而版本 5 使用 SHA1 。
UUIDv4
版本 4 被称为随机变体,因为正如其名称所示,UUID 的值几乎完全随机。不过,第一个例外是 UUID 的第三部分第一个字符,它始终是 4,用来标志 UUID 使用的是版本 4。

UUIDv6
版本 6 与版本 1 几乎相同,唯一不同是记录时间戳的位顺序被翻转了,将时间戳中最重要的部分放置优先。以下图表展示了它们的区别:
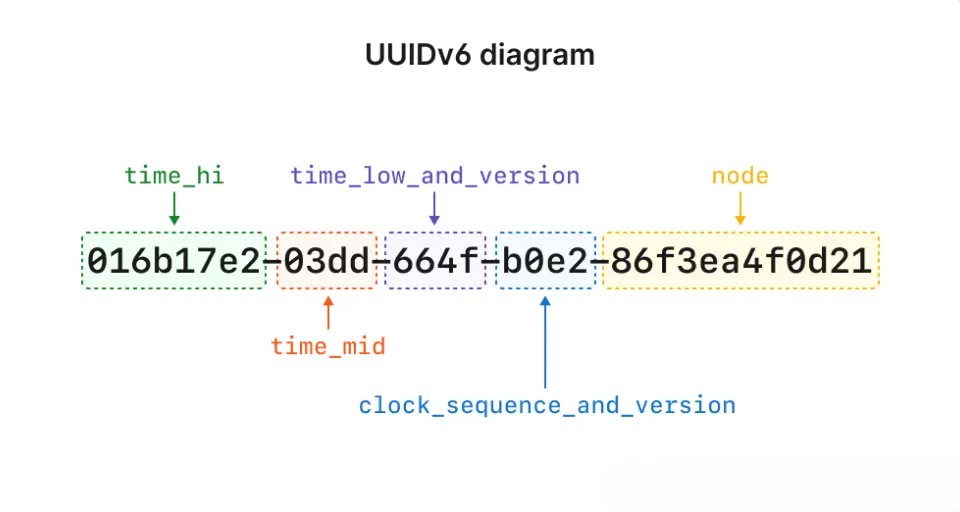
这么做的主要原因是生成一个与版本 1 兼容的值,同时使这些值更具排序性,因为时间戳最重要的部分被放在前面。
UUIDv7
版本 7 也是基于时间的 UUID 变体,但它使用了现代更常见的 Unix 时间戳 (而不是版本 1 中的格里高利日期)。另一个主要不同点是,将表示生成 UUID 系统的 node 替换为随机值,使 UUID 更难追溯到其来源。
UUIDv8
版本 8 是最新版本,它允许厂商特定的实现,同时遵循 RFC 标准。版本 8 的唯一要求是,版本号必须被指定在第三部分的第一个位置,这点和所有其他版本一致。
UUID和MySQL
UUID(大多数情况下)在分布式架构中保证跨系统的唯一性,因此你可能会倾向将其用作记录的主键。然而,与自增整数相比,这样做有一些显而易见的权衡。
插入性能
每当向 MySQL 表插入新记录时,与主键关联的索引需要更新以让查询变得高效。MySQL 中的索引以 B+树 的形式存在,这是一种多层数据结构,能让查询快速找到所需数据。
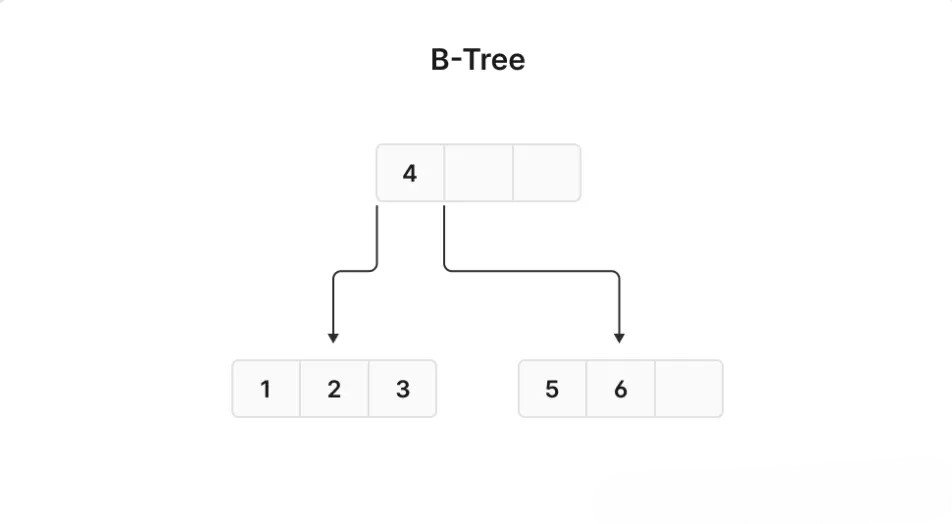
以下图示展示了一个包含 1 到 6 的简单 B-树结构。如果一个查询要求查找值 5,MySQL 从 root 节点开始,将沿右侧路径遍历树以找到目标值。
注: 图示使用的是
B-树而不是B+树。两者的主要区别在于,B+树的叶节点包含对实际数据的引用,而B-树的叶节点则不包含。
当新值(例如 7 到 9)被添加时,MySQL 会拆分右侧节点并重新平衡树结构。
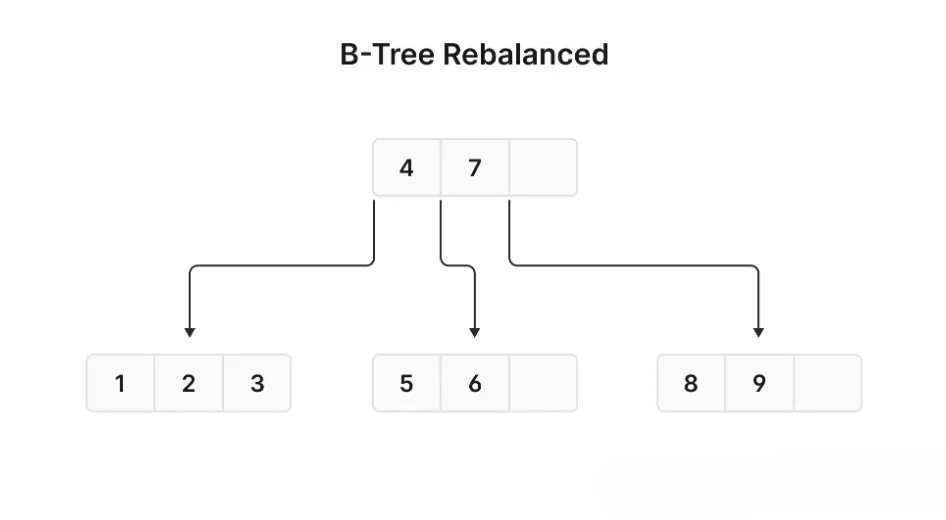
这种过程被称为 页拆分(page splitting) ,其目标是保持 B+树结构的平衡,以便 MySQL 能快速找到所需数据。对于连续值,这种过程相对简单;然而当算法中引入随机性时,MySQL 的树平衡工作可能显著变慢。在一个高流量的数据库上,这可能会影响用户体验,因为 MySQL 试图保持树结构平衡。
更高的存储利用率
MySQL 中的所有主键都是索引。默认情况下,一个自增整数的存储空间为 32 位 。相比之下,UUID 的存储不论是二进制形式还是字符串形式,其占用空间均远大于整数:
- UUID 的二进制形式需要
128位 ,是32位整数的4倍; - 字符串形式,通常为
CHAR(36),需要288位 ,是32位整数的9倍 。
此外,除主键上的默认索引外,次级索引也会占用更多空间。次级索引中使用主键作为指向实际行的指针,意味着主键也需要存储在索引中。如果表中使用 UUID 作为主键,这会显著增加数据库的存储需求,具体取决于表中创建了多少索引。
最后,随机性引发的 页拆分 (如前所述)也会对存储使用和性能造成负面影响。InnoDB 假定主键可以以数字或字典顺序预测性地递增。如果主键是顺序的,InnoDB 会填满页的 94% ,然后创建新页。然而,如果主键是随机的,利用率可能会低至 50% 。因此,使用包含随机性的 UUID 可能导致索引占用过多页资源。
MySQL中使用UUID主键的最佳实践
如果确实需要在表中使用 UUID 作为记录的唯一标识符,可以遵循以下最佳实践来尽量减少负面影响:
使用二进制数据类型
虽然 UUID 经常以 36 字符长的字符串 表示,但它们也可以表示为原生的二进制形式。如果将 UUID 转换为二进制格式,存储在 BINARY(16) 列中,每个值的存储需求将减少到 16 字节 。虽然仍明显大于 32 位整数,但已经远好于存储为 CHAR(36)。
CREATE TABLE uuids(
UUIDAsChar CHAR(36) NOT NULL,
UUIDAsBinary BINARY(16) NOT NULL
);
INSERT INTO uuids SET
UUIDAsChar = 'd211ca18-d389-11ee-a506-0242ac120002',
UUIDAsBinary = UUID_TO_BIN('d211ca18-d389-11ee-a506-0242ac120002');
SELECT * FROM uuids;
-- +--------------------------------------+------------------------------------+
-- | UUIDAsChar | UUIDAsBinary |
-- +--------------------------------------+------------------------------------+
-- | d211ca18-d389-11ee-a506-0242ac120002 | 0xD211CA18D38911EEA5060242AC120002 |
-- +--------------------------------------+------------------------------------+使用有序 UUID 变体
使用支持 排序 的 UUID 版本可以减少使用 UUID 带来的性能和存储影响,因为生成的值更接近于顺序状态,从而避免部分页拆分问题。
即使在多个系统间生成,基于时间的 UUID(例如版本 6 或版本 7)也能保证唯一性,同时尽量保持顺序。有一个例外是 UUID 版本 1,它将时间戳中最不重要部分放置优先。
使用MySQL的内置UUID函数
MySQL 支持直接在 SQL 中生成 UUID,但仅支持版本 1 的值。尽管单独使用它们不是最佳做法,但 MySQL 提供了一个名为 uuid_to_bin 的辅助函数,不仅能将字符串值转换为二进制,还支持使用 “swap flag”(交换标志),使生成的二进制值更具顺序性。
SET @uuidvar = 'd211ca18-d389-11ee-a506-0242ac120002';
-- 不使用 swap flag
SELECT HEX(UUID_TO_BIN(@uuidvar)) AS UUIDAsHex;
-- +----------------------------------+
-- | UUIDAsHex |
-- +----------------------------------+
-- | D211CA18D38911EEA5060242AC120002 |
-- +----------------------------------+
-- 使用 swap flag
SELECT HEX(UUID_TO_BIN(@uuidvar,1)) AS UUIDAsHex;
-- +----------------------------------+
-- | UUIDAsHex |
-- +----------------------------------+
-- | 11EED389D211CA18A5060242AC120002 |
-- +----------------------------------+使用替代的 ID 类型
UUID 不是分布式架构中唯一提供唯一性保障的标识符格式。自 UUID 于 1987 年首次创建以来,已经提出了许多不同的格式,例如 Snowflake ID、ULID 或 NanoID (PlanetScale 使用 NanoID)。
# Snowflake ID
7167350074945572864
# ULID
01HQF2QXSW5EFKRC2YYCEXZK0N
# NanoID
kw2c0khavhql总结
在 MySQL 中使用 UUID 主键在分布式系统中可以几乎确保唯一性;然而它也带来了显著的权衡。幸运的是,通过多个版本的 UUID 以及其替代选项,可以找到更好应对这些权衡的方法,可根据具体的业务场景来选择更好的实践方案。